Managing a Job Grid using Akka
| 15 May 2014 | Tweet |
The Job Grid
Every month Workday’s Integration Cloud Platform (ICP) executes millions of jobs for its hundreds of customers: integration runs, PDF document generations, Payroll calculations and other types of background processing tasks. A feature of the ICP is that it allows customers and their partners to deploy code to Workday, which Workday then runs on their behalf. To achieve this, Workday has deployed a Grid of servers that can be dynamically allocated to tenants based on real-time demand. The Grid provides a scalable, secure, and isolated execution environment for all tenants.
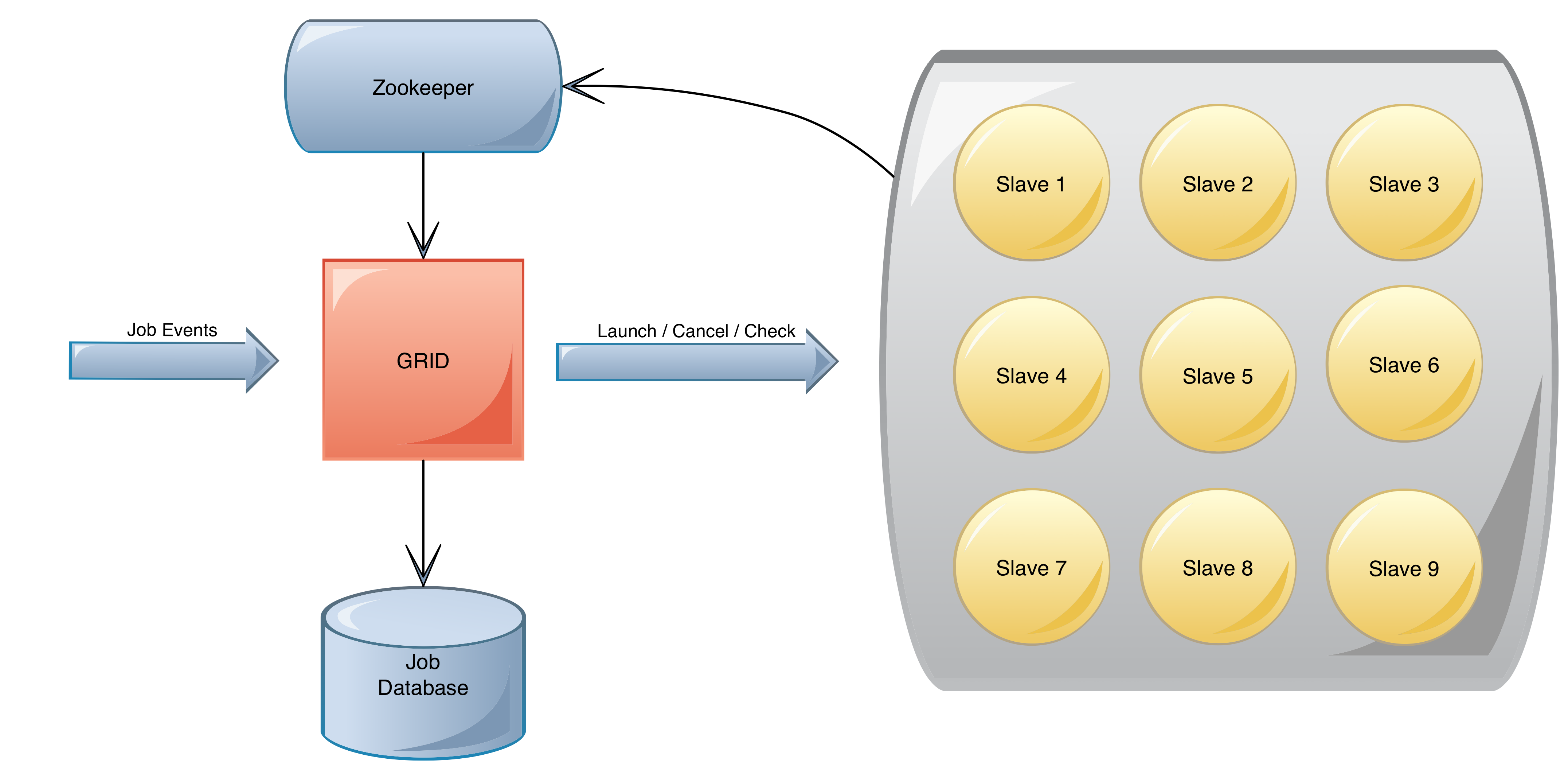
The Grid is a High Availability (HA) clustered application that manages multiple pools of compute resources (Slaves). Different pools have different properties, for example, the size of compute resources, reservation policies, and so on, allowing different styles of background jobs to be handled. Within each pool, the Grid manages:
- Dynamic allocation of Slaves to tenants based on demand
- Queuing and prioritization of jobs
- Supervision of all Slave servers and the jobs they execute
- Handling the state transitions for all jobs
Managing such jobs and compute resources is a complex concurrent and distributed processing problem. While scalability of processing is key, perhaps even more important is to have robust failure handling with clear recovery semantics. In large systems, failures will happen and the Grid must be able to deal with this. For these two reasons, we have chosen the Akka Actor toolkit to implement the management logic for the Grid.
Akka Actors
Akka Actors is a Scala-based implementation of the Actor Model. The Actor Model was defined in the 1973 paper by Carl Hewitt and provides a higher level of abstraction for writing concurrent and distributed systems. Actors provide a framework for creating systems that implement a Share Nothing architecture and are built from the ground up to handle failures. Each actor is responsible for managing its own state and external actors only contact other actors using immutable message passing. Each actor supervises its children, and if the child experiences a failure, the parent handles the recovery of that child.
The Grid Actors
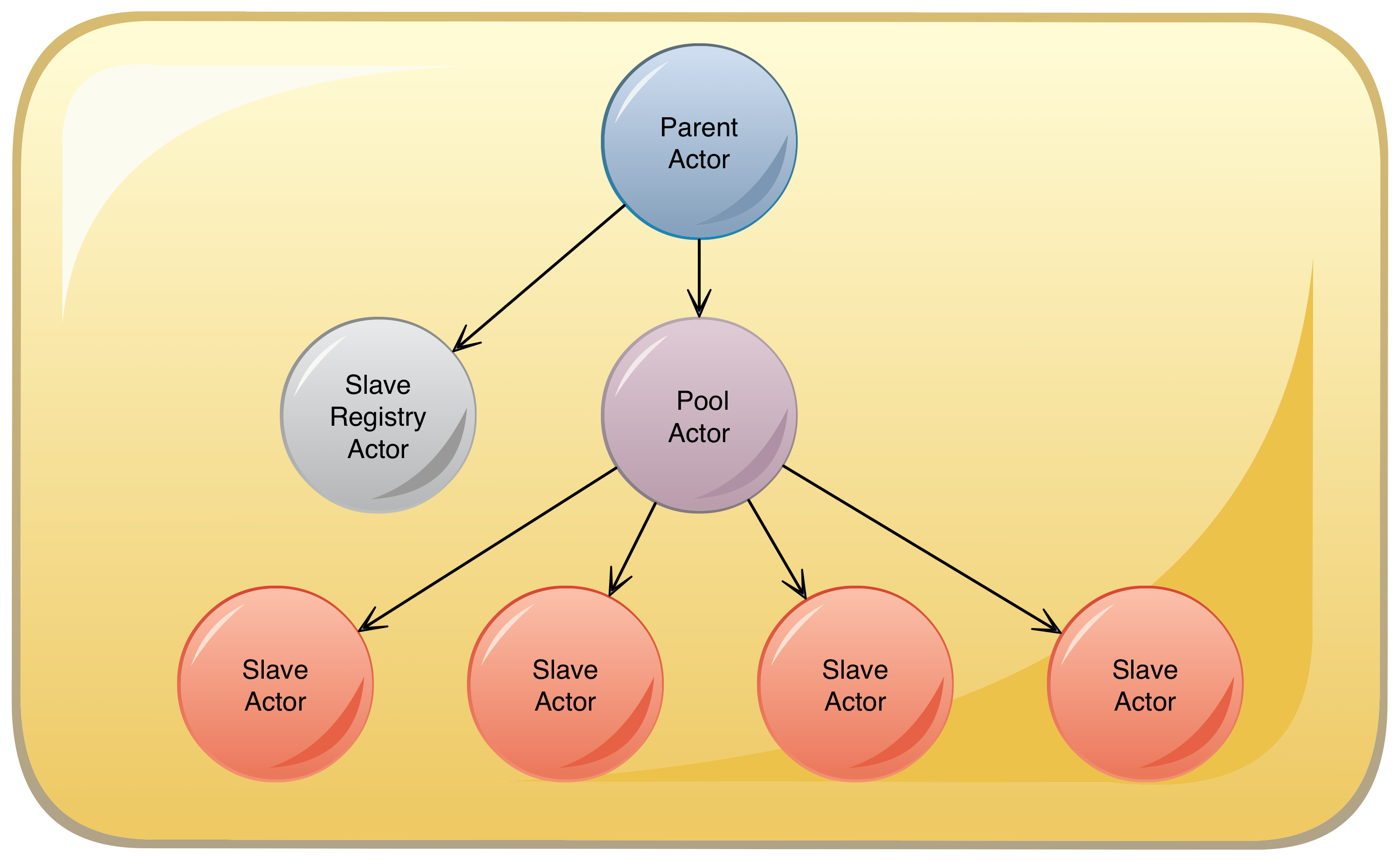
In the Grid Actor hierarchy, each pool of Slaves is represented by a Pool Actor and each remote Slave is represented by a Slave Actor. In addition, a Slave Registry Actor is responsible for alerting the Grid of the existence of new compute resources.
Pool Actor The Grid supports different pool types for different jobs. Each pool type has one Pool Actor. This actor is responsible for:
- Adding and removing Slave Actor children.
- Enqueuing and dequeuing jobs. The pool supports a bounded in-memory queue of jobs to be run. This allows it to make very fast allocation decisions.
- Allocating jobs to Slaves. The allocation logic is pluggable and is customized for each pool type.
Slave Actor
A Slave Actor manages a remote compute Slave. It requests jobs from its Pool Actor parent. When it receives a job, it manages the submission of the job to the remote machine and starts monitoring it. Representing each remote compute resource and job as an actor, allows this processing to occur in parallel, but also helps deal with failure. If there is an error, the Pool Actor parent restarts the Slave Actor. On starting, the Slave Actor attempts to reconnect to the remote compute resource and determine its health and the health of any job it may have been running.
Lessons Learned
Here are some important lessons that we have learned when implementing actor systems:
-
Sweepers: Actor messaging is asynchronous and messages can be missed or received out of order. This is especially true in distributed systems. Consequently, it is important to regularly synchronize your actor’s state with a “source of truth”. In our case, the “source of truth” is the database and we use a sweeper pattern to ensure that the correct state is maintained for all our Jobs and Slaves.
-
Failure handling: Failure handling should not be an afterthought. It is central to how you approach your Actor hierarchy. When handling failures from external systems, to implement your recovery strategy appropriately, it is important to classify the failures. At a minimum, failures must be classified as recoverable versus unrecoverable and limits must be placed on the number of actor restarts in a given period.
-
Tracing: All Actor systems should make use of some form of tracing to help diagnose potential issues in testing and production environments. Numerous Akka tracing libraries are available, but we integrated our Actor logging with the existing Workday logging and monitoring systems.
-
Testing: Testing distributed systems is always difficult and testing for failure is even harder. Akka provides a very powerful Testkit toolkit, to help develop unit tests for failure and recovery handling. We view the testability of Akka-based systems as one of its strongest selling points.
Summary
We hope that this introduction to our Grid technology demonstrates the benefits of using Akka and we look forward to any feedback from the community. We are also using Akka in other parts of our Architecture:
- Task assignment within clusters
- Cluster Routing
- Cluster Singleton
- MapReduce-style processing for parallelizing large or long-running tasks.
We plan to discuss these other use cases in future blog posts.
Acknowledgements
This post was written by Colm Caffrey @colm_c, Grid Architect at Workday. Thanks to Fergal Somers @fergsomers and Workday’s Grid team for their contributions. Many thanks to the Akka team for providing the Akka toolkit.